
Ядерные методы в машинном обучении — это класс алгоритмов распознавания образов, наиболее известным представителем которого является метод опорных векторов (МОВ, англ. SVM). Общая задача распознавания образов — найти и изучить общие типы связей (например, кластеров, ранжирования, главных компонент, корреляций, классификаций) в наборах данных. Для многих алгоритмов, решающих эти задачи, данные, представленные в сыром виде, явным образом преобразуются в представление в виде вектора признаков посредством специфичной схемы распределения признаков, однако ядерные методы требуют только задания специфичного ядра, т.е. функции сходства пар точек данных в сыром представлении.
Ядерные методы получили своё название из-за использования ядерных функций[англ.], которые позволяют им оперировать в неявном пространстве признаков высокой размерности без вычисления координат данных в пространстве, просто вычисляя скалярные произведения между образами всех пар данных в пространстве признаков. Эта операция часто вычислительно дешевле явных вычислений координат. Этот подход называется «ядерным трюком»[1]. Ядерные функции были введены для последовательных данных, графов[англ.], текстов, изображений, а также для векторов.
Среди алгоритмов, способных работать с ядрами, находятся ядерный перцептрон[англ.], методы опорных векторов, гауссовские процессы, метод главных компонент (МГК, англ. PCA), канонический корреляционный анализ, гребневая регрессия, спектральная кластеризация, линейные адаптивные фильтры и многие другие. Любая линейная модель[англ.] может быть переведена в нелинейную модель путём применения к модели ядерного трюка, заменив её признаки (предсказатели) ядерной функцией.
Большинство ядерных алгоритмов базируются на выпуклой оптимизации или нахождении собственных векторов и статистически хорошо обоснованы. Обычно их статистические свойства анализируются с помощью теории статистического обучения (например, используя радемахеровскую сложность[англ.]).
Причины возникновения и неформальное объяснение
Ядерные методы можно рассматривать как обучение на примерах — вместо обучения некоторым фиксированным наборам параметров, соответствующим признакам входа, они «запоминают» -й тренировочный пример и обучают согласно его весам . Предсказание для непомеченного ввода, т.е. не входящего в тренировочное множество, изучается при помощи функции сходства (называемой ядром) между непомеченным входом и каждым из тренировочных входов . Например, ядерный бинарный классификатор обычно вычисляет взвешенную сумму похожести по формуле






- ,

где
- является ядерным бинарным классификатором предсказанной пометки для непомеченного входа , скрытая верная пометка которого нужна;
- является ядерной функцией, которая измеряет схожесть пары входов ;
- сумма пробегает по всем n помеченным примерам в тренировочном наборе классификатора с ;
- являются весами тренировочных примеров, как определено алгоритмом обучения;
- Функция sgn определяет, будет предсказанная классификация положительной или отрицательной.







Ядерные классификаторы были описаны в начале 1960-х годов с изобретением ядерного перцептрона[2]. Они получили большое распространение вместе с популярностью метода опорных векторов в 1990-х годах, когда обнаружили, что МОВ конкурентоспособна с нейронными сетями на таких задачах, как распознавание рукописного ввода.
Математика: ядерный трюк
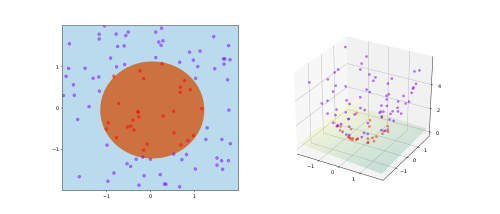
Ядерный трюк избегает явного отображения, которое нужно для получения линейного обучающего алгоритма для нелинейной функции или границы решений[англ.]. Для всех и во входном пространстве некоторые функции могут быть представлены как скалярное произведение в другом пространстве . Функцию часто называют ядром или ядерной функцией. Слово «ядро» используется в математике для обозначения весовой функции или интеграла.




Некоторые задачи машинного обучения имеют дополнительную структуру, а не просто весовую функцию . Вычисления будут много проще, если ядро можно записать в виде "отображения признаков" , которое удовлетворяет равенству


Главное ограничение здесь, что должно быть подходящим скалярным произведением. С другой стороны, явное представление для не обязательно, поскольку является пространством со скалярным произведением. Альтернатива следует из теоремы Мерсера[англ.] — неявно заданная функция существует, если пространство может быть снабжено подходящей мерой, обеспечивающей, что функция удовлетворяет условию Мерсера[англ.].


Теорема Мерсера подобна обобщению результата из линейной алгебры, которое связывает скалярное произведение с любой положительно определённой матрицей. Фактически, условие Мерсера может быть сведено к этому простому случаю. Если мы выбираем в качестве нашей меры считающую меру для всех , которая считает число точек внутри множества , то интеграл в теореме Мерсера сводится к суммированию




Если это неравенство выполняется для всех конечных последовательностей точек в и всех наборов вещественнозначных коэффициентов (сравните, Положительно определённое ядро[англ.]), тогда функция удовлетворяет условию Мерсера.



Некоторые алгоритмы, зависящие от произвольных связей, в исходном пространстве будут, фактически, иметь линейное представление в других условиях — в ранжированном пространстве . Линейная интерпретация даёт нам представление об алгоритме. Более того, часто нет необходимости вычислять прямо во время вычислений, как в случае метода опорных векторов. Некоторые считают уменьшение времени за счёт этого главным преимуществом алгоритма. Исследователи используют его для уточнения смысла и свойств существующих алгоритмов.
Теоретически, матрица Грама по отношению к (иногда называемая «ядерной матрицей»[3]), где , должна быть положительно полуопределена[4]. Эмпирически, для эвристики машинного обучения, выбор функции , которая не удовлетворяет условию Мерсера, может оставаться оправданным, если , по меньшей мере, аппроксимирует интуитивную идею похожести[5]. Независимо от того, является ли ядром Мерсера, о могут продолжать говорить как о «ядре».



Если ядерная функция является также ковариантной функцией[англ.], что используется в гауссовском процессе, тогда матрица Грама может быть названа ковариационной матрицей[6].

Приложения
Области применения ядерных методов разнообразны и включают геостатистику[7], кригинг, метод (обратных) взвешенных расстояний[англ.], трёхмерную реконструкцию, биоинформатику, хемоинформатику, извлечение информации и распознавание рукописного ввода.
Популярные ядра
- Ядро Фишера[англ.]
- Ядро графа[англ.]
- Ядерный сглаживатель[англ.]
- Полиномиальное ядро[англ.]
- Ядро радиальной базисной функции[англ.]
- Строковые ядра
Примечания
- ↑ Theodoridis, 2008, с. 203.
- ↑ Aizerman, Braverman, Rozoner, 1964, с. 821–837.
- ↑ Hofmann, Scholkopf, Smola, 2007.
- ↑ Mohri, Rostamizadeh, Talwalkar, 2012.
- ↑ Sewell, Martin Support Vector Machines: Mercer's Condition. www.svms.org. Дата обращения: 13 октября 2018. Архивировано из оригинала 15 октября 2018 года.
- ↑ Rasmussen, Williams, 2006.
- ↑ Honarkhah, Caers, 2010, с. 487–517.
Литература
- Aizerman M. A., Emmanuel M. Braverman, Rozoner L. I. Theoretical foundations of the potential function method in pattern recognition learning // Automation and Remote Control. — 1964. — Т. 25. — С. 821–837. Процитировано в статье
- Isabelle Guyon, B. Boser, Vladimir Vapnik. Automatic capacity tuning of very large VC-dimension classifiers // Advances in neural information processing systems. — 1993.
- Sergios. Pattern Recognition. — Elsevier B.V., 2008. — ISBN 9780080949123.
- Mehryar Mohri, Afshin Rostamizadeh and Ameet Talwalkar. . — Cambridge, London: MIT press, 2012. — (Adaptive Computation and Machine Learning). — ISBN 978-0-262-01825-8.
- Thomas Hofmann, Bernhard Scholkopf, Alexander J. Smola. Kernel Methods in Machine Learning // The Annals of Statistics. — 2007. — Январь (т. 36, вып. 3).
- Rasmussen C. E., Williams C. K. I. Gaussian Processes for Machine Learning. — Cambridge, London: MIT Press, 2006. — (Adaptive Computation and Machine Learning). — ISBN 0-262-18253-X.
- Honarkhah M., Caers J. Stochastic Simulation of Patterns Using Distance-Based Pattern Modeling // Mathematical Geosciences. — 2010. — Т. 42. — doi:10.1007/s11004-010-9276-7.
Литература
- John Shawe-Taylor, Nello Cristianini. Kernel Methods for Pattern Analysis. — Cambridge University Press, 2004.
- Liu W., Principe J., Haykin S. Kernel Adaptive Filtering: A Comprehensive Introduction. — Wiley, 2010.
Ссылка
- Kernel-Machines Org — community website
- www.support-vector-machines.org (Literature, Review, Software, Links related to Support Vector Machines - Academic Site)
- onlineprediction.net Kernel Methods Article
| Задачи | |
|---|---|
| Обучение с учителем | |
| Кластерный анализ | |
| Снижение размерности | |
| Структурное прогнозирование | |
| Выявление аномалий | |
| Графовые вероятностные модели | |
| Нейронные сети | |
| Обучение с подкреплением |
|
| Теория | |
| Журналы и конференции |
|
Обычно почти сразу, изредка в течении часа.